How to use the URL Filter feature
When using OpenSearchServer's web crawler, such tabs as Pattern list or Exclusion list are easy to understand.
However the URL filter tab is trickier. Here are hints to better understand this feature.
We will use this set of URL filter rules as our example:
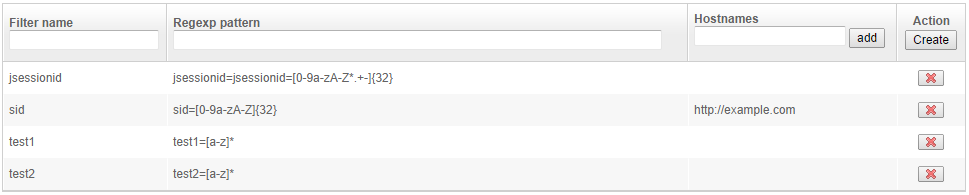
When to use an URL filter
URL filter is a great way to delete junk information from URLs, and prevent it from causing duplication.
A common case is when a website does not define any canonical URL (to help search engines avoid duplication) and appends a jsessionid parameter to every URL. In such a situation, the web crawler may encounter multiple links to the same page, which only differ by this jessionid parameter.
Filtering these parameters out allows for clean management of the URLs database - and will considerably speed up the crawling process.
Caveats
One should keep in mind that:
- Exclusion rules must be written as a regular expression.
- If no
hostnameis provided, then a rule will be applied for every hostname. - Regular expression tests are applied to every parameter found in the query string, one by one. OpenSearchServer defines a parameter as any string that follows the character
?or the character;(the latter is often used forjsessionidparameters). - Regular expressions are thus not applied to the whole URL. The parameters are extracted from the URL, then made available for testing against each regular expression.
- In our example, the text
test1=housewould be removed from the URLhttp://something.com/stuff?test1=house&userid=45but not from the URLhttp://something.com/stuff/test1=house/. In the first URL it comes after a question mark and is thus considered a parameter. In the second URL it doesn't, and is considered to just be part of the URL. - It is critical to understand that URLs are tested against URL filter rules as soon as they are discovered by the web crawler.
- Thus, those parameters that match our example regular expressions are stripped from URLs before these URLs are handed over to the
URL Browser. - Which means that during subsequent sessions, the crawler will crawl URLs that have been cleaned by the filters.
- If you use the
URL Patterntab to insert URLs whose parameters would normally be deleted, these URLs will not be tested against the filters. Same thing when crawling an URL using theManual crawltab: the URL filters will be bypassed.