How to parse YouTube URLs and extract data
Here are step-by-step instructions:
- Create a new field to index the data you need. In this example we'll index the videos' titles.
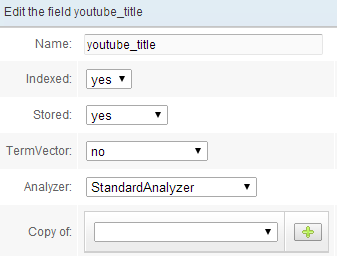
- Create a new analyzer
- Be sure to choose KeywordTokenizer for indexation.
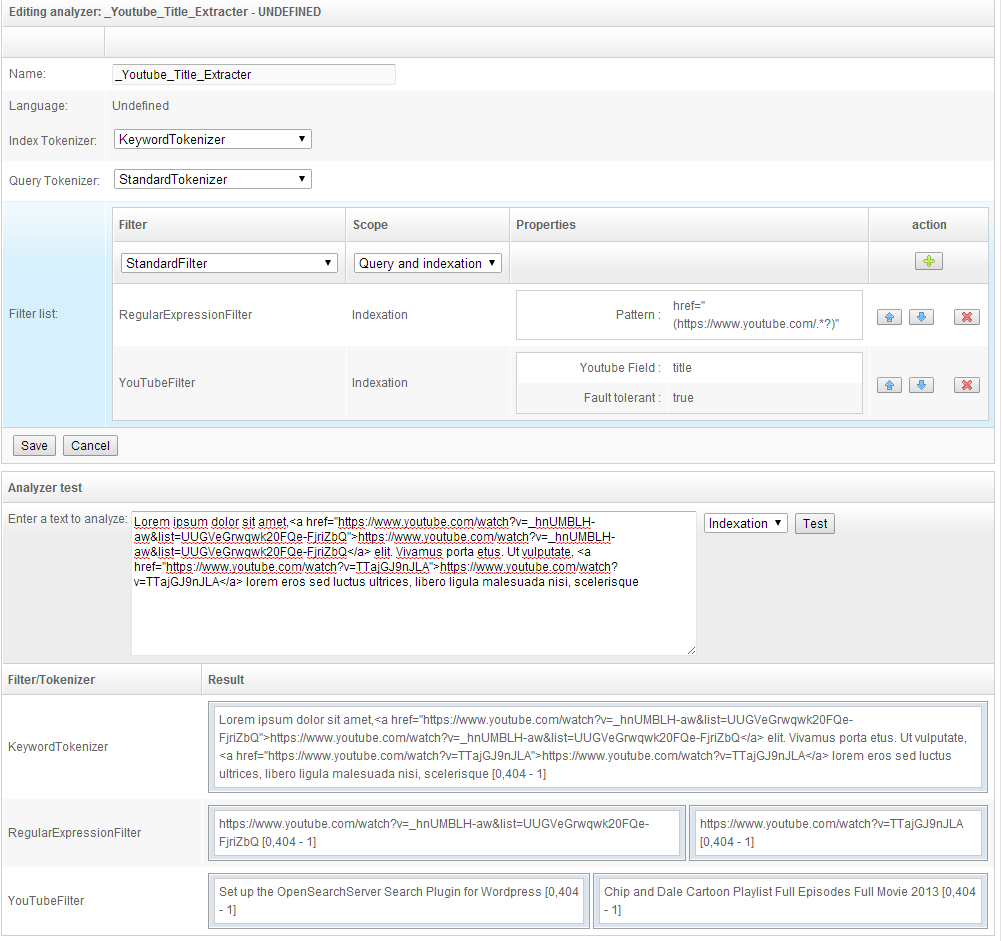
- You can see how it all works in the test section at the bottom. The filter
YouTube filterwill make calls to YouTube's API to retrieve information about those YouTube videos it found links toward in the analyzed text. These links are identified using a regular expression.
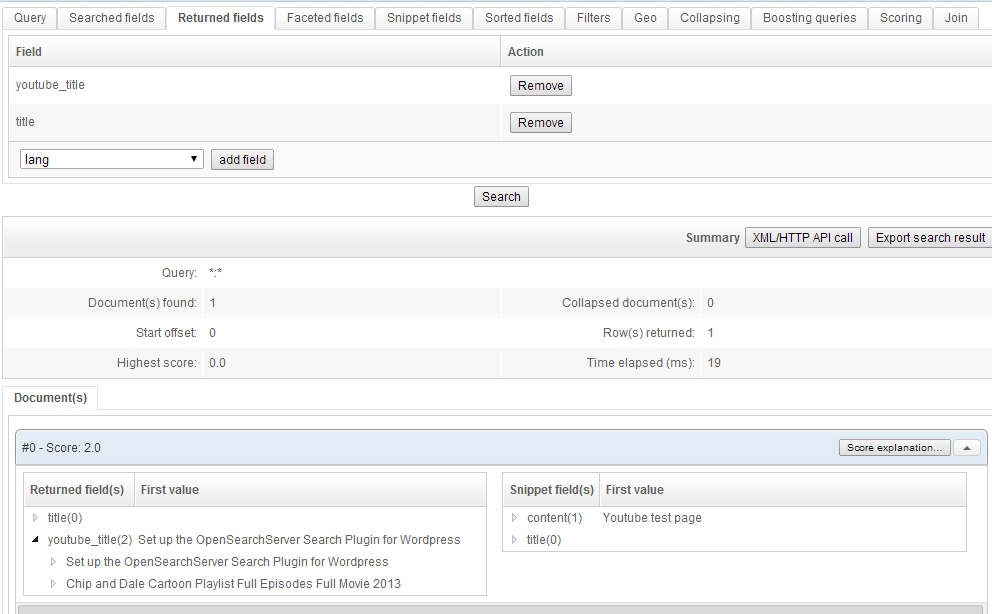
- In the HTML parser add a mapping between
htmlSourceand your new field, and use the newly created analyzer on this mapping. This will automatically extract any YouTube links from the full HTML source code of those webpages.

- You can now index pages containing links to videos hosted by YouTube. These videos' YouTube titles will be extracted and indexed in your new field.
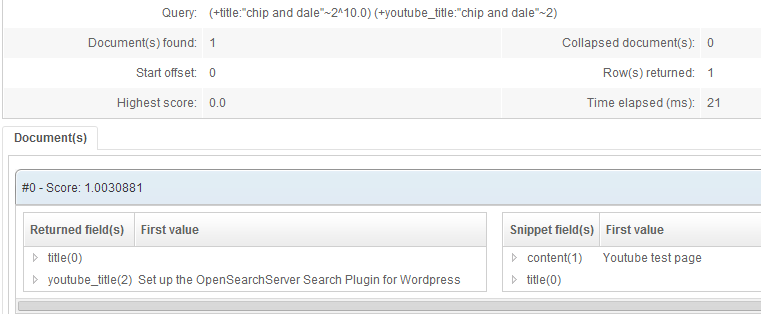
In the example below there are two titles in one document, since the indexed page contains two YouTube links.
If one is searching for the YouTube title of the video, the document linking toward it will be found. This is feasible since the YouTube title was properly tokenized by the StandardTokenizer set on the field.