How to exclude part of a Web page from being crawled
OpenSearchServer allows you to skip certain parts of a webpage while crawling.
Excluding content using the opensearchserver.ignore CSS class
The content of any HTML tag with the class opensearchserver.ignore will be ignored while crawling.
The opensearchserver.ignore class can be stacked with other CSS classes.
Examples:
<div class="opensearchserver.ignore">This div will not be indexed in OpenSearchServer.</div>
<div class="content opensearchserver.ignore">This content class div will not be indexed in OpenSearchServer.</div>
Excluding content using XPATH requests
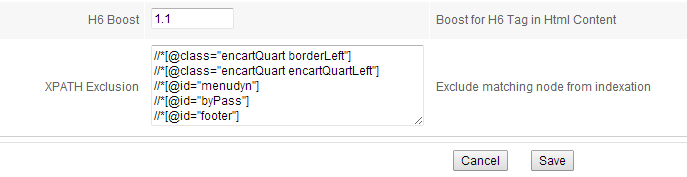
HTML parsers allow for exclusion of parts of webpages via XPATH requests. In the OpenSearchServer UI, this option can be found under Schema > HTML Parser > Parser Attributes > XPATH Exclusion, at the bottom of the page. One XPATH request can be written per line.
Those parts of webpages matching these requests will be totally ignored by the HTML parser.